简单理解 RL 中的 KL 散度估计器:从数值估计到梯度估计

在强化学习中,KL 散度的估计方式直接影响训练稳定性。本文系统剖析三种经典估计器 $k_1, k_2, k_3$ 在 on-policy 和 off-policy 场景的性质差异,并给出「用于 reward 惩罚」与「用于 loss 回传」时的选型指南。

引言:KL 散度在强化学习中的角色
在策略优化(PPO、GRPO 等)或对齐训练(RLHF/RLAIF)中,KL 惩罚是约束新策略不偏离参考策略的核心手段,用以防止训练不稳定或策略崩溃。
正向 KL 与反向 KL 的区别
设 $q_\theta$ 为当前 actor 策略,$p$ 为参考策略,两种方向的 KL 散度分别为:
反向 KL(Reverse KL): \(D_{\mathrm{KL}}(q_\theta \| p) = \mathbb{E}_{x \sim q_\theta}\left[\log \frac{q_\theta(x)}{p(x)}\right]\)
正向 KL(Forward KL): \(D_{\mathrm{KL}}(p \| q_\theta) = \mathbb{E}_{x \sim p}\left[\log \frac{p(x)}{q_\theta(x)}\right]\)
直觉理解:
- 反向 KL 倾向于「模式寻优」(mode-seeking)——策略会集中在参考分布的高概率区域,可能牺牲多样性
- 正向 KL 倾向于「质量覆盖」(mass-covering)——策略会尽量覆盖参考分布的支撑集
在 RLHF 的主流实现中,反向 KL 更为常见,因为我们希望 actor 不要偏离 reference policy 太远,而非要求完全覆盖所有模式。
三种估计器的定义与设计原理
设比值 $r(x) = \frac{p(x)}{q_\theta(x)}$,John Schulman 提出的三种单样本估计子定义如下:
$k_1$:最朴素的估计器
\[k_1(x) = -\log r = \log q_\theta(x) - \log p(x)\]这是最直接的定义——直接取 log-ratio 的负值。它对反向 KL 无偏,但有一个致命缺陷:可能取负值,而 KL 散度始终非负。这导致其方差极高,因为正负样本会相互抵消。
$k_2$:基于 f-散度的低方差估计器
\[k_2(x) = \frac{1}{2}(\log r)^2\]设计动机:$k_1$ 的问题在于可正可负,而 $k_2$ 通过取平方保证每个样本都是正的,直观上每个样本都在告诉你 $p$ 和 $q$ 相差多远。
为什么偏差很小? $k_2$ 本质上是一个 f-散度(f-divergence),其中 $f(x) = \frac{1}{2}(\log x)^2$。f-散度有一个优美的性质:所有可微的 f-散度在 $q \approx p$ 时,二阶展开都形如
\[D_f(p, q_\theta) = \frac{f^{\prime\prime}(1)}{2} \theta^T F \theta + O(\theta^3)\]其中 $F$ 是 Fisher 信息矩阵。KL 散度对应 $f(x) = -\log x$,有 $f^{\prime\prime}(1) = 1$;而 $k_2$ 对应的 $f(x) = \frac{1}{2}(\log x)^2$,同样有 $f^{\prime\prime}(1) = 1$。这意味着当策略接近时,$k_2$ 与真实 KL 的行为几乎一致,偏差仅体现在高阶项。
$k_3$:控制变量法构造的「最优」估计器
\[k_3(x) = r - 1 - \log r\]设计动机:我们想要一个既无偏又低方差的估计器。标准做法是给 $k_1$ 加一个控制变量(control variate)——一个期望为零但与 $k_1$ 负相关的量。
注意到 $\mathbb{E}_q[r - 1] = \mathbb{E}_q\left[\frac{p}{q}\right] - 1 = 1 - 1 = 0$,所以对于任意 $\lambda$,
\[k_1 + \lambda(r - 1) = -\log r + \lambda(r - 1)\]仍然是无偏估计。
为什么选 $\lambda = 1$? 由于 $\log$ 是凹函数,有 $\log x \leq x - 1$,因此
\[k_3 = (r - 1) - \log r \geq 0\]始终非负!这保证了每个样本都在「正向」贡献信息,消除了 $k_1$ 正负抵消的问题。
几何直觉:$k_3$ 实际上是一个 Bregman 散度。考虑凸函数 $\phi(x) = -\log x$,它在 $x=1$ 处的切线为 $y = 1 - x$。Bregman 散度定义为「函数值与切线值之差」:
\[\begin{aligned} D_\phi(r, 1) &= \phi(r) - \phi(1) - \phi'(1)(r - 1) \\ &= -\log r - 0 - (-1)(r - 1) \\ &= r - 1 - \log r \\ &= k_3. \end{aligned}\]由于凸函数始终位于其切线上方,这个差值天然非负。更重要的是,在 $r \to 1$ 时,函数与切线「贴合」得越来越紧,差值以 $(r-1)^2$ 的二阶速度趋近于零——这正是 $k_3$ 在策略接近时方差小的根本原因。
三者对比总结
| 估计器 | 定义 | 设计原理 | 对数值的偏差 | 方差特性 |
|---|---|---|---|---|
| $k_1$ | $\log r$ | 最朴素定义 | 无偏 | 高(可正可负) |
| $k_2$ | $\frac{1}{2}(\log r)^2$ | f-散度,二阶行为与 KL 一致 | 有偏(但极小) | 低(恒正) |
| $k_3$ | $r - 1 - \log r$ | 控制变量 + Bregman 散度 | 无偏 | 低(恒正) |
从数值估计的角度看,$k_3$ 是「无偏 + 低方差」的最优选择;但正如后文将分析的,梯度层面的故事完全不同。
核心分析
估计 KL 数值时的偏差与方差
假设从 $q_\theta$ 采样来估计反向 KL $D_{\mathrm{KL}}(q_\theta | p)$:
无偏性分析:
\[\begin{aligned} \mathbb{E}_{q}[k_1] &= \mathbb{E}_{q}\left[\log \frac{q}{p}\right] = D_{\mathrm{KL}}(q \| p) \quad \textbf{(无偏)}\\ \mathbb{E}_{q}[k_3] &= \mathbb{E}_{q}[r - 1 - \log r] \\ &= 1 - 1 + D_{\mathrm{KL}}(q \| p) \\ &= D_{\mathrm{KL}}(q \| p) \quad \textbf{(无偏)}\\ \mathbb{E}_{q}[k_2] &= \frac{1}{2}\mathbb{E}_{q}[(\log r)^2] \neq D_{\mathrm{KL}}(q \| p) \quad \textbf{(有偏)} \end{aligned}\]结论:对于估计反向 KL 的数值,$k_1$ 和 $k_3$ 是无偏估计,而 $k_2$ 是有偏的。
方差特性的 Trade-off:
John Schulman 的实验($q = \mathcal{N}(0,1)$,$p = \mathcal{N}(0.1,1)$,真实 KL = 0.005)表明:
| 估计器 | bias/true | stdev/true |
|---|---|---|
| $k_1$ | 0 | 20 |
| $k_2$ | 0.002 | 1.42 |
| $k_3$ | 0 | 1.42 |
当 KL 较大时($p = \mathcal{N}(1,1)$,真实 KL = 0.5):
| 估计器 | bias/true | stdev/true |
|---|---|---|
| $k_1$ | 0 | 2 |
| $k_2$ | 0.25 | 1.73 |
| $k_3$ | 0 | 1.7 |
核心直觉:
- $k_1 = -\log r$ 以一阶项起步,当 $r$ 接近 1 时波动较大,且可能取负值
- $k_3 = r - 1 - \log r$ 在 $r=1$ 处是二阶小量,始终非负,因此在策略接近时方差更小
- 但当覆盖严重不足($r$ 可能爆炸)时,$k_3$ 的方差会被权重爆炸拖累;此时 $k_1$ 反而更稳定
注:若要估计正向 KL 的数值 $D_{\mathrm{KL}}(p | q) = \mathbb{E}_p[\log r]$,而只能从 $q$ 采样,可用重要性采样 $\mathbb{E}_q[r \log r]$。
估计 KL 梯度时的关键区分
这是最容易混淆、也是实践中最关键的部分。 本节先分析从 $q_\theta$ 采样(on-policy)的情形,后文将进一步讨论从行为策略 $\mu$ 采样(off-policy)时的变化。
正向与反向 KL 真梯度的推导
在分析估计器之前,我们先推导正向和反向 KL 散度对 $\theta$ 的真梯度作为参照。
记 score function $s_\theta(x) = \nabla_\theta \log q_\theta(x)$,它有一个重要性质:$\mathbb{E}_{q_\theta}[s_\theta] = 0$(因为 $\int \nabla_\theta q_\theta dx = \nabla_\theta \int q_\theta dx = \nabla_\theta 1 = 0$)。
反向 KL 的梯度:
\[D_{\mathrm{KL}}(q_\theta \| p) = \int q_\theta(x) \log \frac{q_\theta(x)}{p(x)} dx\]对 $\theta$ 求梯度(使用乘积法则):
\[\nabla_\theta D_{\mathrm{KL}}(q_\theta \| p) = \int \nabla_\theta q_\theta \cdot \log \frac{q_\theta}{p} dx + \int q_\theta \cdot \nabla_\theta \log \frac{q_\theta}{p} dx\]利用 $\nabla_\theta q_\theta = q_\theta \cdot s_\theta$ 以及 $\nabla_\theta \log q_\theta = s_\theta$、$\nabla_\theta \log p = 0$:
\[= \mathbb{E}_q\left[s_\theta \cdot \log \frac{q_\theta}{p}\right] + \mathbb{E}_q[s_\theta] = \mathbb{E}_q\left[s_\theta \cdot \log \frac{q_\theta}{p}\right]\]即:
\[\boxed{\nabla_\theta D_{\mathrm{KL}}(q_\theta \| p) = \mathbb{E}_q\left[s_\theta \cdot \log \frac{q_\theta}{p}\right] = -\mathbb{E}_q[s_\theta \cdot \log r]}\]正向 KL 的梯度:
\[D_{\mathrm{KL}}(p \| q_\theta) = \int p(x) \log \frac{p(x)}{q_\theta(x)} dx\]由于 $p(x)$ 不依赖于 $\theta$:
\[\nabla_\theta D_{\mathrm{KL}}(p \| q_\theta) = \int p(x) \cdot \nabla_\theta \left(-\log q_\theta(x)\right) dx = -\mathbb{E}_p[s_\theta]\]为了用 $q$ 的样本估计这个量,进行重要性采样:
\[-\mathbb{E}_p[s_\theta] = -\mathbb{E}_q\left[\frac{p}{q_\theta} \cdot s_\theta\right] = -\mathbb{E}_q[r \cdot s_\theta]\]利用 $\mathbb{E}_q[s_\theta] = 0$,可改写为:
\[\boxed{\nabla_\theta D_{\mathrm{KL}}(p \| q_\theta) = \mathbb{E}_q[(1-r) \cdot s_\theta]}\]有了这两个结果,我们就能判断各估计器的梯度期望究竟对应哪个 KL 的真梯度。
两种求导顺序
在代码实现中,存在两条路径:
- 先梯度、后期望:对每个样本的 $k_i(x)$ 求梯度,再对梯度求期望(Monte Carlo 估计)
- 先期望、后梯度:把 $\mathbb{E}_q[k_i]$ 当作损失函数,对解析表达式求梯度
在典型的深度学习代码中,我们实际执行的是「先梯度、后期望」——自动微分对每个样本计算梯度,然后在 batch 上取平均。
三种估计器的梯度推导
现在我们计算三种估计器的梯度,看它们的期望分别对应哪个 KL 的真梯度。
推导 $\nabla_\theta k_1$:
\[k_1 = -\log r = -\log \frac{p(x)}{q_\theta(x)} = \log q_\theta(x) - \log p(x)\] \[\nabla_\theta k_1 = \nabla_\theta \log q_\theta(x) - \nabla_\theta \log p(x) = s_\theta - 0 = s_\theta\]推导 $\nabla_\theta k_2$:
\[k_2 = \frac{1}{2}(\log r)^2\]由链式法则:
\[\begin{aligned} \nabla_\theta k_2 &= (\log r) \cdot \nabla_\theta(\log r) \\ &= (\log r) \cdot \nabla_\theta(\log p(x) - \log q_\theta(x)) \\ &= (\log r)(-s_\theta) \\ &= - (\log r) s_\theta. \end{aligned}\]推导 $\nabla_\theta k_3$:
\[k_3 = r - 1 - \log r\]首先计算 $\nabla_\theta r$。由于 $r = p(x) \cdot q_\theta(x)^{-1}$:
\[\nabla_\theta r = p(x) \cdot (-1) \cdot q_\theta(x)^{-2} \cdot \nabla_\theta q_\theta(x) = -\frac{p(x)}{q_\theta(x)} \cdot \frac{\nabla_\theta q_\theta(x)}{q_\theta(x)} = -r \cdot s_\theta\]再计算 $\nabla_\theta \log r$:
\[\nabla_\theta \log r = \frac{1}{r} \nabla_\theta r = \frac{1}{r} \cdot (-r \cdot s_\theta) = -s_\theta\]因此:
\[\nabla_\theta k_3 = \nabla_\theta r - 0 - \nabla_\theta \log r = -r \cdot s_\theta - (-s_\theta) = (1 - r) \cdot s_\theta\]对它们在 $q_\theta$ 下取期望:
| Estimator | $\mathbb{E}_{q}[\nabla_\theta k_i]$ | Equals |
|---|---|---|
| $k_1$ | $\mathbb{E}_{q}[s_\theta] = 0$ | Zero (useless as loss) |
| $k_2$ | $-\mathbb{E}_{q}[(\log r) \cdot s_\theta] = \nabla_\theta D_{\mathrm{KL}}(q \| p)$ | Gradient of reverse KL |
| $k_3$ | $\mathbb{E}_{q}[(1-r) \cdot s_\theta] = \nabla_\theta D_{\mathrm{KL}}(p \| q)$ | Gradient of forward KL |
关键洞察:
- $k_2$ 的梯度等价于反向 KL 的真梯度——这是优化「约束策略不偏离 ref」的正确选择
- $k_3$ 的梯度等价于正向 KL 的真梯度——这对应「覆盖型」目标
- $k_1$ 的梯度期望恒为零——作为 loss 反传毫无意义!
「先期望后梯度」vs「先梯度后期望」
如果从解析角度把 $\mathbb{E}_q[k_i]$ 当作一个关于 $\theta$ 的函数再求梯度(即「先期望后梯度」),那么:
\[\nabla_\theta \mathbb{E}_q[k_1] = \nabla_\theta D_{\mathrm{KL}}(q \| p)\] \[\nabla_\theta \mathbb{E}_q[k_3] = \nabla_\theta D_{\mathrm{KL}}(q \| p)\]两者都给出反向 KL 的梯度。但在代码中直接对 $k_3$ 的样本均值调用反传时,自动微分执行的是「先梯度后期望」,得到的是 $\mathbb{E}_q[\nabla_\theta k_3]$,即正向 KL 的梯度。
这个区分非常重要:同一个估计器,两种求导顺序可能给出完全不同的结果。
扩展:从行为策略 $\mu$ 采样时的 KL 梯度估计
前面的分析都默认样本来自当前策略 $q_\theta$。然而在实际 RL 训练中,我们常常遇到这样的 off-policy 场景:
- 用旧策略或混合策略生成数据,再更新当前 actor $q_\theta$
- 离线 RL / 经验回放中,样本分布固定为 $\mu$,而不是当前的 $q_\theta$
这时,如果我们仍然希望优化反向 KL $D_{\mathrm{KL}}(q_\theta | p)$,就必须引入重要性权重。
关于大模型 off-policy 场景的深入分析,可以参考我之前的博客:从两策略到三策略:LLM RL 中行为策略–参考策略不一致下的 TRPO 扩展。
设置与记号
仍然沿用前文的记号,现在加入采样分布 $\mu(x)$,并定义重要性权重
\[w(x) = \frac{q_\theta(x)}{\mu(x)}\]当从 $x \sim \mu$ 采样时,用 $w(x) k_i(x)$ 的 batch 均值作为 loss,然后调用自动微分。那么三种估计器分别给出什么梯度?
一个关键差异是:
以前的期望是 $\mathbb{E}_{q_{\theta}}[\cdot]$,分布本身依赖 $\theta$; 现在的期望是 $\mathbb{E}_{\mu}[\cdot]$,而 $\mu$ 与 $\theta$ 无关。
这会让「先期望后梯度」与「先梯度后期望」的关系发生根本变化。
关键观察:两种求导顺序的等价性
因为 $\mu$ 与 $\theta$ 无关,对任何关于 $\theta$ 可微的函数 $f_\theta(x)$,有
\[\nabla_\theta \mathbb{E}_{\mu}[f_\theta(x)] = \mathbb{E}_{\mu}[\nabla_\theta f_\theta(x)]\]换句话说,代码中对样本均值反传(先梯度后期望)就等价于对解析形式求梯度(先期望后梯度),不会再像 on-policy 时那样分裂成两个不同的结果。
所以在 off-policy + 重要性加权 的情形下,对反向 KL 数值无偏的估计器 $k_1$ 和 $k_3$,它们的梯度期望都将对应于反向 KL 的真梯度。
这是与 on-policy 情形的根本区别。
数值层面:无偏性仍然保持
由标准的重要性采样关系 $\mathbb{E}_\mu[w \cdot f] = \mathbb{E}_{q_\theta}[f]$,有
\[\mathbb{E}_\mu[w k_1] = D_{\mathrm{KL}}(q_\theta \| p), \quad \mathbb{E}_\mu[w k_3] = D_{\mathrm{KL}}(q_\theta \| p) \quad \textbf{(无偏)}\] \[\mathbb{E}_\mu[w k_2] = \mathbb{E}_{q_\theta}[k_2] \neq D_{\mathrm{KL}}(q_\theta \| p) \quad \textbf{(有偏)}\]这与 on-policy 情形完全一致。
梯度推导
首先计算重要性权重的梯度。由 $w = q_\theta / \mu$ 且 $\mu$ 不依赖 $\theta$:
\[\nabla_\theta w(x) = w(x) s_\theta(x)\]结合前文已推导的 $\nabla_\theta k_i$,用乘积法则:
$\nabla_\theta(w k_1)$:
\[\nabla_\theta(w k_1) = (\nabla_\theta w) k_1 + w (\nabla_\theta k_1) = w s_\theta k_1 + w s_\theta = w s_\theta (k_1 + 1)\]$\nabla_\theta(w k_2)$:
\[\nabla_\theta(w k_2) = w s_\theta k_2 + w (-\log r) s_\theta = w s_\theta (k_2 - \log r)\]$\nabla_\theta(w k_3)$:
\[\nabla_\theta(w k_3) = w s_\theta k_3 + w (1-r) s_\theta = w s_\theta (k_3 + 1 - r)\]代入 $k_3 = r - 1 - \log r$:
\[k_3 + 1 - r = (r - 1 - \log r) + 1 - r = -\log r = k_1\]因此有一个漂亮的简化:
\[\boxed{\nabla_\theta(w k_3) = w s_\theta k_1 = -w s_\theta \log r}\]哪些给出无偏的反向 KL 梯度?
利用 $\mathbb{E}_\mu[w \cdot f] = \mathbb{E}_{q_\theta}[f]$ 和 $\mathbb{E}_{q_\theta}[s_\theta] = 0$:
$\mathbb{E}_\mu[\nabla_\theta(w k_1)]$:
\[\mathbb{E}_\mu[w s_\theta (k_1 + 1)] = \mathbb{E}_{q}[s_\theta k_1] + \underbrace{\mathbb{E}_{q}[s_\theta]}_{=0} = \nabla_\theta D_{\mathrm{KL}}(q_\theta \| p) \quad \checkmark\]$\mathbb{E}_\mu[\nabla_\theta(w k_2)]$:
\[\mathbb{E}_\mu[w s_\theta (k_2 - \log r)] = \mathbb{E}_{q}[s_\theta (k_2 - \log r)] = \nabla_\theta \mathbb{E}_{q}[k_2]\]这是 $\mathbb{E}_q[k_2]$ 这个 f-散度的真梯度,不是反向 KL 的梯度。
$\mathbb{E}_\mu[\nabla_\theta(\bar{w} k_2)]$($\bar{w} = \text{sg}(w)$ 表示 detach):
如果把重要性权重视为常数(在代码中 detach 掉),则:
\[\nabla_\theta(\bar{w} k_2) = \bar{w} \cdot \nabla_\theta k_2 = \bar{w} \cdot (-\log r) s_\theta\]取期望:
\[\mathbb{E}_\mu[\bar{w} \cdot (-\log r) s_\theta] = \mathbb{E}_{q}[(-\log r) s_\theta] = \nabla_\theta D_{\mathrm{KL}}(q_\theta \| p) \quad \checkmark\]这正是反向 KL 的真梯度!
$\mathbb{E}_\mu[\nabla_\theta(w k_3)]$:
\[\mathbb{E}_\mu[w s_\theta k_1] = \mathbb{E}_{q}[s_\theta k_1] = \nabla_\theta D_{\mathrm{KL}}(q_\theta \| p) \quad \checkmark\]总结表格:
| 加权估计器 | 期望对应的目标 | 梯度期望对应的真梯度 |
|---|---|---|
| $\frac{q_\theta}{\mu} k_1$ | $D_{\mathrm{KL}}(q_\theta \| p)$ | $\nabla_\theta D_{\mathrm{KL}}(q_\theta \| p)$(反向 KL) ✓ |
| $\frac{q_\theta}{\mu} k_2$ | $\mathbb{E}_q[k_2]$(f-散度) | $\nabla_\theta \mathbb{E}_q[k_2]$,不是反向 KL ✗ |
| $\text{sg}\left(\frac{q_\theta}{\mu}\right) k_2$ | $\mathbb{E}_q[k_2]$(f-散度) | $\nabla_\theta D_{\mathrm{KL}}(q_\theta \| p)$(反向 KL) ✓ |
| $\frac{q_\theta}{\mu} k_3$ | $D_{\mathrm{KL}}(q_\theta \| p)$ | $\nabla_\theta D_{\mathrm{KL}}(q_\theta \| p)$(反向 KL) ✓ |
与 on-policy 情形的对比——一个有趣的反转:
- On-policy 时,用 $k_2$ 做 loss 的梯度是反向 KL,而 $k_1$ 的梯度期望恒为零
- Off-policy + 重要性加权时,$\frac{q_\theta}{\mu} k_1$ 和 $\frac{q_\theta}{\mu} k_3$ 给出反向 KL 的真梯度,而 $\frac{q_\theta}{\mu} k_2$(权重参与梯度计算)不再适用
- 但如果把重要性权重 detach 掉,$\text{sg}\left(\frac{q_\theta}{\mu}\right) k_2$ 的梯度也是反向 KL 的真梯度
三个无偏梯度估计器的方差对比
前一小节我们看到,在 off-policy + 重要性采样的设置下,下面三个 loss 都给出反向 KL 的无偏梯度估计:
\[L_1(x) = w(x) k_1(x),\qquad L_2(x) = \bar w(x) k_2(x),\qquad L_3(x) = w(x) k_3(x),\]其中 $w = \dfrac{q_\theta}{\mu}$,$\bar w = \mathrm{sg}(w)$ 表示对权重做 stop-gradient。它们对应的梯度随机变量为:
\[g_1(x) := \nabla_\theta L_1(x),\quad g_2(x) := \nabla_\theta L_2(x),\quad g_3(x) := \nabla_\theta L_3(x).\]利用前文已推导的结果:
- $\nabla_\theta w = w s_\theta$;
- $\nabla_\theta k_1 = s_\theta$;
- $\nabla_\theta k_2 = - (\log r) s_\theta = k_1 s_\theta$;
- $\nabla_\theta k_3 = (1-r) s_\theta$.
有:
\[\begin{aligned} g_1(x) &= \nabla_\theta(w k_1) = w s_\theta k_1 + w s_\theta = w(x) s_\theta(x)\big(k_1(x)+1\big),\\ g_2(x) &= \nabla_\theta(\bar w k_2) = \bar w \,\nabla_\theta k_2 = w \, k_1 s_\theta = w(x) s_\theta(x) k_1(x),\\ g_3(x) &= \nabla_\theta(w k_3) = w s_\theta k_3 + w(1-r)s_\theta = w s_\theta (k_3 + 1 - r) = w(x) s_\theta(x) k_1(x). \end{aligned}\]最后一步用到了 $k_3 + 1 - r = (r - 1 - \log r) + 1 - r = -\log r = k_1$。于是出现了一个非常关键的事实:
在 off-policy + detach 权重的情况下,$\bar w k_2$ 与 $w k_3$ 的梯度完全一样:$g_2(x) \equiv g_3(x)$。
换言之,三个 loss 实际上只对应两种不同的梯度随机变量:$g_1$ 与 $g_\star := g_2 = g_3$。
下面就比较这两种随机变量的方差。
为简化记号,令
\[A(x) := w(x) s_\theta(x), \quad B(x) := k_1(x),\]则
\[g_1 = A(B+1),\qquad g_\star = A B.\]两者的期望都等于 $\nabla_\theta D_{\mathrm{KL}}(q_\theta|p)$,因此有相同的均值项。展开方差定义并相减得到:
\[\boxed{ \mathrm{Var}_\mu(g_1) - \mathrm{Var}_\mu(g_\star) = \mathbb{E}_\mu\big[A^2((B+1)^2 - B^2)\big] = \mathbb{E}_\mu\big[A^2 (2B+1)\big] }\]也就是
\[\mathrm{Var}_\mu(g_1) - \mathrm{Var}_\mu(g_\star) = \mathbb{E}_\mu\Big[w(x)^2 s_\theta(x)^2 \big(2k_1(x)+1\big)\Big].\]在常见的 KL 惩罚 regime 下,$q_\theta \approx p \approx \mu$,取 $r(x)=1+\varepsilon(x)$,$\lvert \varepsilon\rvert \ll1$。此时 $k_1 = -\log r \approx -\varepsilon$,因此 $2k_1+1 \approx 1 - 2\varepsilon$,主导项为正的 $O(1)$ 常数。这意味着上式右侧近似为 $\mathbb{E}_\mu[w^2 s_\theta^2] > 0$,从而 $\mathrm{Var}_\mu(g_1) > \mathrm{Var}_\mu(g_\star)$。
更具体地,一阶近似
\[k_1 \approx -\varepsilon,\quad k_1+1 \approx 1-\varepsilon.\]于是
\[g_1(x) \approx w(x) s_\theta(x)(1 - \varepsilon(x)),\quad g_\star(x) \approx w(x) s_\theta(x)(-\varepsilon(x)).\]核心直觉:
- $g_1$ 包含一个量级为 $O(1)$ 的零均值噪声项 $w s_\theta$,导致单样本方差较大;
- $g_\star$ 已把该常数噪声项消去,剩下与 $\varepsilon$ 成正比的一阶小量,方差为 $O(\varepsilon^2)$,显著更小。
小结表格:
| 估计器 | 梯度随机变量 | 系数量级($r\approx1$) | 方差 |
|---|---|---|---|
| $w k_1$ | $w s_\theta (k_1+1)$ | $O(1)$ | 高 |
| $\mathrm{sg}(w) k_2$ | $w s_\theta k_1$ | $O(\varepsilon)$ | 低 |
| $w k_3$ | $w s_\theta k_1$ | $O(\varepsilon)$ | 低 |
结论:在 off-policy + 重要性采样的设置下,给出反向 KL 真梯度的无偏估计器有三个:$w k_1,\; \bar w k_2,\; w k_3$。其中 $\bar w k_2$ 与 $w k_3$ 在梯度层面完全等价——同均值、同方差、同高阶矩;相比之下,$w k_1$ 的梯度多了一个零均值的常数噪声项 $w s_\theta$,在典型的 KL 惩罚 regime 下其方差大约高一个量级。
实践建议:若在 off-policy 场景下优化反向 KL,首选 $w k_3$ 或 $\mathrm{sg}(w) k_2$(两者梯度等价且方差低);$w k_1$ 虽无偏但方差高,可作为备选并需配合 clipping/正则化。
极度 off-policy 时的警示:
当 $\mu$ 与 $q_\theta$ 差异很大——比如 $\mu$ 在 $q_\theta$ 的高密度区域几乎没有采样,或 $w = q_\theta / \mu$ 在尾部爆炸——任何基于 $\frac{q_\theta}{\mu}$ 的方法都会遭遇严重的方差问题。此时 $\frac{q_\theta}{\mu} k_3$(或 $\mathrm{sg}\left(\frac{q_\theta}{\mu}\right) k_2$)相对 $\frac{q_\theta}{\mu} k_1$ 的优势不再有理论保证,需要结合 clipping、正则化等策略综合处理。
不过,在 RL 实践中我们通常会控制 KL 约束、限制 off-policy 程度(比如使用近邻策略 $\mu = q_{\theta_\text{old}}$),在这个常见的 regime 里,可以相当有信心地说:
如果已经决定用 off-policy + 重要性采样来优化反向 KL,推荐使用 $\dfrac{q_\theta}{\mu} k_3$ 或 $\mathrm{sg}\left(\dfrac{q_\theta}{\mu}\right) k_2$(两者梯度等价且方差低);相较之下,$\dfrac{q_\theta}{\mu} k_1$ 方差更高。
这就是为什么 DeepSeek v3.2 技术报告中使用的是 $\frac{q_\theta}{\mu} k_3$ 作为 off-policy KL 惩罚的估计器。
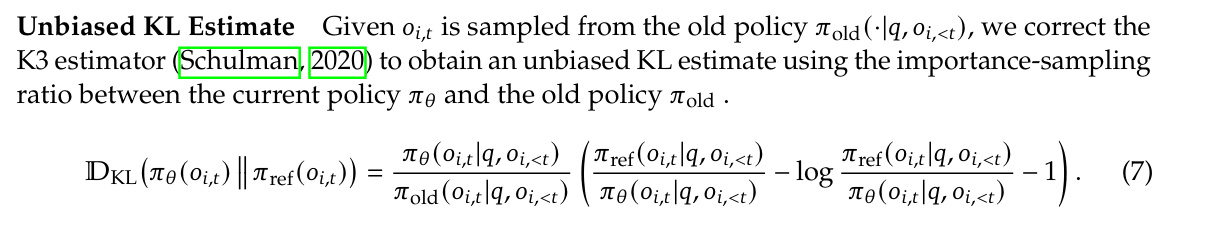
小结
- 从行为策略 $\mu$ 采样时,自然的 off-policy KL 估计为 $\frac{q_\theta}{\mu} k_i$。
- 数值上,$\frac{q_\theta}{\mu} k_1$ 与 $\frac{q_\theta}{\mu} k_3$ 仍然是反向 KL 的无偏估计。
- 梯度上,因为 $\mu$ 与 $\theta$ 无关,「先期望后梯度」与「先梯度后期望」等价:
- $\mathbb{E}_\mu[\nabla_\theta(\frac{q_\theta}{\mu} k_1)] = \nabla_\theta D_{\mathrm{KL}}(q_\theta | p)$
- $\mathbb{E}_\mu[\nabla_\theta(\frac{q_\theta}{\mu} k_3)] = \nabla_\theta D_{\mathrm{KL}}(q_\theta | p)$
- $\mathbb{E}_\mu[\nabla_\theta(\frac{q_\theta}{\mu} k_2)] \neq \nabla_\theta D_{\mathrm{KL}}(q_\theta | p)$
- 方差上,$\frac{q_\theta}{\mu} k_3$ 与 $\mathrm{sg}\left(\frac{q_\theta}{\mu}\right) k_2$ 的梯度完全相同(两者都是 $w s_\theta k_1$),在统计性质上等价。相比之下,$\frac{q_\theta}{\mu} k_1$ 的梯度多了一个零均值噪声项 $w s_\theta$,在 $q_\theta \approx p \approx \mu$ 的典型场景下方差显著更高。
梯度估计总览
下表汇总了 on-policy 与 off-policy 两种场景下,各估计器的梯度期望及其对应的优化目标:
| 采样来源 | Loss | $\nabla_\theta$ Loss 的期望 | 对应的优化目标 | 能否用于优化反向 KL? |
|---|---|---|---|---|
| $q$ (on) | $k_1$ | $\mathbb{E}_q[s_\theta] = 0$ | 无(梯度恒为零) | ✗ |
| $q$ (on) | $k_2$ | $\nabla_\theta D_{\mathrm{KL}}(q \| p)$ | 反向 KL | ✓ |
| $q$ (on) | $k_3$ | $\nabla_\theta D_{\mathrm{KL}}(p \| q)$ | 正向 KL | ✗ |
| $\mu$ (off) | $\frac{q}{\mu} k_1$ | $\nabla_\theta D_{\mathrm{KL}}(q \| p)$ | 反向 KL | ✓(但方差较高) |
| $\mu$ (off) | $\frac{q}{\mu} k_2$ | $\nabla_\theta \mathbb{E}_q[k_2]$ | f-散度(非 KL) | ✗ |
| $\mu$ (off) | $\text{sg}\left(\frac{q}{\mu}\right) k_2$ | $\nabla_\theta D_{\mathrm{KL}}(q \| p)$ | 反向 KL | ✓ |
| $\mu$ (off) | $\frac{q}{\mu} k_3$ | $\nabla_\theta D_{\mathrm{KL}}(q \| p)$ | 反向 KL | ✓(推荐,低方差) |
关键结论:
- On-policy 优化反向 KL:唯一正确选择是 $k_2$
- Off-policy 优化反向 KL:有三个正确选项:
- $\frac{q}{\mu} k_1$:无偏但方差较高
- $\text{sg}\left(\frac{q}{\mu}\right) k_2$:无偏,与 $\frac{q}{\mu} k_3$ 梯度完全等价
- $\frac{q}{\mu} k_3$:无偏且方差更低(与上一项等价,均为推荐选择)
- $\frac{q}{\mu} k_2$(权重参与梯度)在 off-policy 下失效:这是一个容易被忽视的陷阱
RL 实践指南
KL 作为 Reward 惩罚(不需要梯度)
当 KL 仅作为标量惩罚加入 reward shaping 时,我们只需要准确的数值估计,不需要反传梯度。
推荐:
- 使用 $k_1$ 或 $k_3$(两者对反向 KL 数值均无偏)
- 当策略已接近参考策略时,$k_3$ 往往更低方差
- 覆盖不足或尾部错配明显时,$k_1$ 更稳健
- Off-policy 时加重要性权重 $\frac{q_\theta}{\mu}$ 即可
注:若想施加正向 KL 惩罚(偏向覆盖行为分布),数值上可用 $\mathbb{E}_q[r \log r]$ 或(若可从 $p$ 采样)$\mathbb{E}_p[\log r]$。
KL 作为 Loss(需要梯度回传)
当 KL 作为 loss 的一部分参与反传时,必须考虑梯度的正确性。
On-policy:优化反向 KL(最常见场景)
目标:控制 actor 不偏离 reference policy。
正确做法:使用 $k_2$ 作为 loss。
\[\mathcal{L}_{k_2} = \frac{1}{2}(\log r)^2\]其梯度期望 $\mathbb{E}_q[\nabla k_2] = \nabla_\theta D_{\mathrm{KL}}(q | p)$ 正是反向 KL 的真梯度。
On-policy:优化正向 KL(覆盖型场景)
目标:让策略覆盖参考分布的支撑集(如离线 RL、模仿学习等)。
正确做法:使用 $k_3$ 作为 loss。
\[\mathbb{E}_q[\nabla k_3] = \mathbb{E}_q[(1-r) \cdot s_\theta] = \nabla_\theta D_{\mathrm{KL}}(p \| q)\]直接对 $k_3$ 的样本均值调用反传,自动微分计算的就是 $\mathbb{E}_q[\nabla_\theta k_3]$,即正向 KL 的梯度,无需额外处理。
Off-policy:优化反向 KL
目标:数据来自行为策略 $\mu$,仍希望优化反向 KL。
推荐做法:使用 $\dfrac{q_\theta}{\mu} k_3$ 或 $\mathrm{sg}\left(\dfrac{q_\theta}{\mu}\right) k_2$ 作为 loss(两者梯度完全等价)。
\[\mathcal{L} = \dfrac{q_\theta(x)}{\mu(x)} \cdot \left(\dfrac{p(x)}{q_\theta(x)} - 1 - \log \dfrac{p(x)}{q_\theta(x)}\right)\]或
\[\mathcal{L} = \mathrm{sg}\left(\dfrac{q_\theta(x)}{\mu(x)}\right) \cdot \dfrac{1}{2}\left(\log \dfrac{p(x)}{q_\theta(x)}\right)^2\]- 梯度无偏
- 在 $q_\theta \approx p$ 时方差都显著更低
备选方案:使用 $\dfrac{q_\theta}{\mu} k_1$(梯度同样无偏,但方差更高)
避免:使用 $\dfrac{q_\theta}{\mu} k_2$(权重参与梯度计算)——梯度有偏,不是反向 KL 的正确方向
一份「拿来就用」的对照表
| 目标 | 采样来源 | 用于数值 | 用于梯度 |
|---|---|---|---|
| 反向 KL $D_{\mathrm{KL}}(q \| p)$ | $q$(on-policy) | $k_1$ 或 $k_3$(无偏) | $k_2$ |
| 反向 KL $D_{\mathrm{KL}}(q \| p)$ | $\mu$(off-policy) | $\frac{q}{\mu} k_1$ 或 $\frac{q}{\mu} k_3$(无偏) | $\frac{q}{\mu} k_3$(推荐)或 $\text{sg}\left(\frac{q}{\mu}\right) k_2$ |
| 正向 KL $D_{\mathrm{KL}}(p \| q)$ | $q$ | $\mathbb{E}_q[r\log r]$ | $k_3$ |
常见实现陷阱
陷阱 1:把 $k_1$ 直接当 loss 反传(on-policy)
$k_1$ 的梯度期望恒为零($\mathbb{E}_q[\nabla k_1] = \mathbb{E}_q[s_\theta] = 0$),作为 loss 完全无效。
解决:reward shaping 用 $k_1$ 或 $k_3$(不需要梯度),loss 用 $k_2$ 或 $k_3$。
陷阱 2:混淆 $k_3$ 的「数值无偏性」与「梯度对应的目标」
$k_3$ 对反向 KL 的数值是无偏估计,但它的梯度对应的是正向 KL。如果你的目标是优化反向 KL,却用 $k_3$ 作为 loss,实际上在优化正向 KL。
解决:明确你的优化目标。优化反向 KL 用 $k_2$;优化正向 KL 才用 $k_3$。
陷阱 3:$r$ 重尾导致方差爆炸
当策略与参考分布差异过大时,$r = p/q$ 可能出现极端值,导致 $k_3$ 的方差爆炸。
解决:控制 KL 约束,或对 $r$ 进行 clipping。
陷阱 4:离策略下仍用 $k_2$ 或 $\frac{q_\theta}{\mu} k_2$(权重参与梯度)
在 on-policy 下,$k_2$ 是优化反向 KL 的正确选择。但如果数据来自 $\mu \neq q_\theta$:
- 直接用 $k_2$(不加权):期望不是在 $q_\theta$ 下取的,估计器完全失效
- 用 $\frac{q_\theta}{\mu} k_2$(权重参与梯度计算):梯度有偏,不是反向 KL 的真梯度
解决:离策略场景下,改用 $\frac{q_\theta}{\mu} k_3$(推荐)、$\text{sg}\left(\frac{q_\theta}{\mu}\right) k_2$(将权重 detach)或 $\frac{q_\theta}{\mu} k_1$。
陷阱 5:对重要性权重的 detach 处理不当
代码实现中,$w = q_\theta / \mu$ 通常通过 log_prob_q - log_prob_mu 再取 exp 计算得到。是否对 $w$ 进行 detach 会导致完全不同的结果:
- 使用 $k_1$ 或 $k_3$ 时:$w$ 应该参与梯度计算(不要 detach),否则会丢失 $\nabla_\theta w = w s_\theta$ 这一项,导致梯度错误
- 使用 $k_2$ 时:$w$ 应该被 detach,这样才能得到反向 KL 的真梯度。如果让 $w$ 参与梯度计算,得到的是 f-散度的梯度,不是反向 KL
总结:选择不同的估计器时,要注意匹配正确的 detach 策略。
总结
一句话记忆:
- 只要数值(KL 作为 reward 惩罚):选 $k_1$ 或 $k_3$(均对反向 KL 无偏);off-policy 时加重要性权重即可
- 需要梯度(KL 作为 loss):
- On-policy:优化反向 KL → 用 $k_2$;优化正向 KL → 用 $k_3$
- Off-policy:优化反向 KL → 用 $\frac{q_\theta}{\mu} k_3$ 或 $\text{sg}\left(\frac{q_\theta}{\mu}\right) k_2$(两者梯度等价,均为无偏 + 低方差的推荐选择)
把「从谁采样」、「估计谁的值」、「对谁求梯度」这三个问题捋清楚,三种估计器就不再让人混淆了。特别注意:on-policy 和 off-policy 下,优化反向 KL 的正确选择是不同的——前者用 $k_2$,后者用 $\frac{q_\theta}{\mu} k_3$ 或 $\text{sg}\left(\frac{q_\theta}{\mu}\right) k_2$。
参考文献
-
Dibya Ghosh. “KL Divergence for Machine Learning”. https://dibyaghosh.com/blog/probability/kldivergence
-
John Schulman. “Approximating KL Divergence”. https://joschu.net/blog/kl-approx.html
-
Verl Documentation. “Proximal Policy Optimization (PPO)”. https://verl.readthedocs.io/en/latest/algo/ppo.html
-
初七123334. RLHF/RLVR 训练中的 KL 近似方法浅析(k1 / k2 / k3). https://zhuanlan.zhihu.com/p/1966872846212010437
-
Kezhao Liu, Jason Klein Liu, Mingtao Chen, Yiming Liu. “Rethinking KL Regularization in RLHF: From Value Estimation to Gradient Optimization”. https://arxiv.org/abs/2510.01555
-
Yifan Zhang, Yiping Ji, Gavin Brown, et al. “On the Design of KL-Regularized Policy Gradient Algorithms for LLM Reasoning”. https://arxiv.org/abs/2505.17508
@misc{WangZhang2025KLEstimators,
author = {Wang, Xihuai and Zhang, Shao},
title = {Understanding {KL} Divergence Estimators in {RL}: From Value Approximation to Gradient Estimation},
year = {2025},
month = dec,
day = {01},
url = {https://xihuai18.github.io/reinforcement-learning/2025/12/01/kl-estimators-en.html}
}