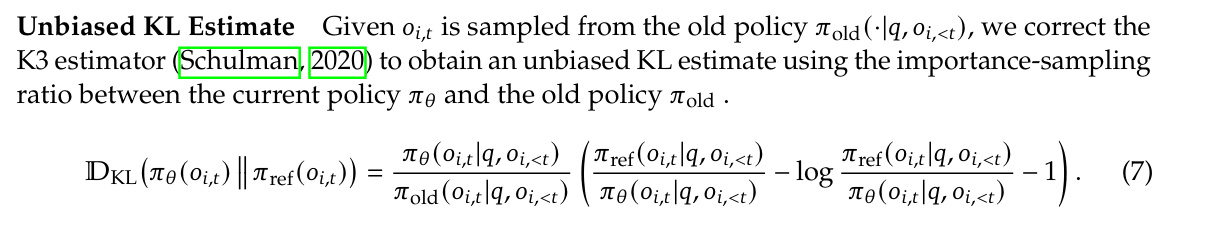Choosing KL Estimators in RL: From Value Unbiasedness to Gradient Correctness
In RL, KL estimators should not be judged only by how accurately they estimate KL values, but also by what objective their gradients actually optimize. This post compares k1, k2, k3 in on-policy and off-policy settings, and turns the result into a practical selection guide.
In RL, KL estimators should not be judged only by how accurately they estimate KL values, but also by what objective their gradients actually optimize. This post compares three estimators $k_1, k_2, k_3$ in both on-policy and off-policy settings, and shows how the answer changes depending on whether KL is used as a differentiable loss term or as a detached reward-shaping term.
1. Introduction: The Role of KL Divergence in Reinforcement Learning
This post is really about one implementation-level question: when code says “add a KL penalty,” why can changing the estimator, changing the sampling distribution, or adding a single .detach() quietly change the optimization target? In policy optimization (PPO, GRPO, etc.) and alignment training (RLHF/RLAIF), a KL penalty looks like a straightforward regularizer that keeps the current policy close to a reference. But once you implement it, several choices immediately branch apart: which estimator ($k_1$, $k_2$, $k_3$), which sampling distribution (on-policy vs. off-policy), and how the KL term enters optimization (as a differentiable loss term vs. as a detached reward-shaping term).
To make that question precise, we need to separate two issues: estimating the value of a KL term, and understanding which objective its gradient actually optimizes. In many implementations those are not the same thing.
1.1 The Distinction Between Forward KL and Reverse KL
Let $q_\theta$ be the current actor policy, $p$ the reference policy. The two directions of KL divergence are:
Reverse KL is mode-seeking: the policy concentrates on high-probability regions of $p$, possibly sacrificing diversity.
Forward KL is mass-covering: the policy tries to cover the support of $p$.
RLHF typically uses reverse KL because we want the actor not to stray too far from the reference, rather than requiring it to cover every mode.
1.2 Three Choices That Change the Answer
It helps to think of KL implementation as three choices: who the samples come from, which KL direction you care about, and whether KL is backpropagated directly or only used as a reward coefficient. Change any one of them, and the recommended estimator may change too.
Who to sample from? Do samples come from the current policy $q_\theta$ (on-policy), or from a behavior policy $\mu$ (off-policy)?
What to estimate? Are we trying to estimate reverse KL $D_{\mathrm{KL}}(q_\theta \| p)$ or forward KL $D_{\mathrm{KL}}(p \| q_\theta)$?
How to use it? Is the KL term used as a differentiable loss term, or as a detached reward-shaping term (stop-gradient)?
Scope: This post focuses on token/sample-level KL terms and their behavior inside the main policy-gradient term. I only comment briefly on learned critics, GAE, baseline normalization, and fully rigorous off-policy correction for general multi-step MDPs.
Unlike classic notes that mainly discuss KL approximation as a value-estimation problem, this post is closer to the recent LLM-RL question of gradient correctness: once the same estimator moves from a reward coefficient to a differentiable loss term, is it still optimizing the objective you think it is?
Bottom line first (only for the token/sample-level KL terms discussed here)
If the target is reverse KL and KL is a differentiable loss term: in the naive on-policy implementation, use $k_2$; if you explicitly construct $\rho$, prefer $\rho k_3$ or $\mathrm{sg}(\rho)k_2$.
If KL is used as stop-gradient reward shaping: for the policy-gradient term itself, only $k_1$ stays aligned with reverse-KL regularization.
In the other common configurations, the issue is often not a slightly worse value estimate, but that the gradient is optimizing a different objective.
1.3 First Fix the Problem With Three Questions
To make the post easier to read, start with three questions before looking at any derivation:
Question
If the answer is…
What can go wrong?
Does KL backpropagate directly?
Directly: KL is a loss; not directly: KL is reward shaping or a metric
The same $k_i$ has different gradient semantics in loss and reward form
Where do samples come from?
From $q_\theta$ means on-policy; from $\mu$ means off-policy
Off-policy requires separating the target distribution from the sampling distribution
Which direction is being regularized?
Reverse KL, forward KL, or a local surrogate
The KL value being estimated need not match the gradient direction of the loss
These three questions determine all recommendations below. The main mental model is:
$$
\text{KL value estimator} \neq \text{KL optimization objective} \neq \text{gradient actually returned by code}.
$$
The rest of the post repeatedly checks whether these three objects coincide.
2. Cheat Sheet (Skim-and-Go)
The three tables below condense the entire operational guidance of the post. A minimal notation primer is given first so you can read them, pick the recommended writing for your setting, and dive back into the derivations later.
Notation primer (full definitions in the next chapter):
$q_\theta$: current policy; $p$: reference policy; $\mu$: sampling policy (on-policy means $\mu = q_\theta$).
Note: $k_2$ and $\frac{q_\theta}{\text{sg}(q_\theta)} k_3$ have identical gradients (sample-level equivalent). For on-policy, directly using $k_2$ is recommended as the simplest approach.
2.2 Off-Policy Reverse KL as a Loss Term
Loss Writing
Pros
Cons
Rec.
$\frac{q_\theta}{\mu} k_1$
Correct gradient (reverse KL), value unbiased
Higher variance
△
$\frac{q_\theta}{\mu} k_2$
—
Gradient matches a local second-order surrogate, not reverse KL
✗✗
$\text{sg}\left(\frac{q_\theta}{\mu}\right) k_2$
Correct gradient (reverse KL), low variance
Value biased (but bias is minimal)
✓✓
$\frac{q_\theta}{\mu} k_3$
Correct gradient (reverse KL), low variance, value unbiased
—
✓✓
Note: $\text{sg}\left(\frac{q_\theta}{\mu}\right) k_2$ and $\frac{q_\theta}{\mu} k_3$ have identical gradients (sample-level equivalent). Both are recommended choices.
2.3 KL as Reward Shaping (stop-gradient)
Estimator
Pros
Cons
Rec.
$k_1$
Value unbiased, policy-gradient term unbiased
Higher variance
✓✓
$k_2$
Value biased
Policy-gradient term biased
✗✗
$k_3$
Value unbiased, low variance
Policy-gradient term biased, bias term is $-\nabla D_{\mathrm{KL}}(p\|q)$, adds non-target gradient terms
✗✗
Note: For the stop-gradient reward-shaping setup analyzed here, only $k_1$ keeps the policy-gradient term aligned with reverse-KL regularization. Both $k_2$ and $k_3$ introduce bias in that term; even though $k_3$ is value-unbiased with low variance, it theoretically already deviates from the target gradient.
Legend: ✓✓ strongly recommended; ✓ recommended (slightly more complex or minor drawback); △ usable with caution; ✗✗ does not match the objective discussed here.
For derivations, variance analysis, and common pitfalls, keep reading.
3. Preliminaries: Notation and Basic Concepts
Before getting into the analysis, let’s fix the notation and write down two basic results that will be used throughout.
3.1 Notation, Sampling Distribution, and the True Gradient of the Objective
Notation:
$q_\theta$: Current actor policy (parameterized by $\theta$)
$q$: When unambiguous, we write $q := q_\theta$
$p$: Reference policy (independent of $\theta$)
$\mu$: Behavior policy for off-policy sampling (independent of $\theta$)
$s_\theta(x) = \nabla_\theta \log q_\theta(x)$: Score function
$\text{sg}(\cdot)$: Stop-gradient operation (.detach() in code)
A Unified Perspective on Sampling Policies: Introducing the $\rho$ Notation
When analyzing KL-estimator gradients, on-policy and off-policy may look like separate cases, but they can be handled in one framework.
Introduce the sampling policy $\mu$, meaning data are drawn from $x \sim \mu$. Define the unified ratio:
The key insight is: in both on-policy and off-policy analyses, we treat the sampling policy $\mu$ as a gradient constant (i.e., apply stop-gradient to $\mu$).
Off-policy ($\mu \neq q_\theta$): $\mu$ is inherently independent of $\theta$, so $\text{sg}(\mu) = \mu$, giving $\rho = \frac{q_\theta}{\mu}$
On-policy ($\mu = q_\theta$): Set $\mu = q_\theta$ but stop its gradient, so $\rho = \frac{q_\theta}{\text{sg}(q_\theta)} \equiv 1$ (numerically always 1), while still having $\nabla_\theta \rho = s_\theta \neq 0$
In the on-policy case, even though $\rho \equiv 1$ numerically, you must explicitly construct $\rho = \frac{q_\theta}{\text{sg}(q_\theta)}$ (or equivalently $\rho = \exp(\log q_\theta - \text{sg}(\log q_\theta))$) in the computation graph. If you replace it with the literal constant 1, you cut off the score-function path, causing the derivation to degenerate to the “naive on-policy implementation” described later.
What $\rho$ restores is the gradient path coming from the sampling distribution’s dependence on $\theta$. In the on-policy case, that missing path is exactly why expect-then-differentiate and differentiate-then-expect can disagree.
With this notation in place, the rest of the derivation no longer needs two separate tracks.
Score Function and True KL Gradients
The score function has an important property: $\mathbb{E}_{q_\theta}[s_\theta] = 0$ (since $\int \nabla_\theta q_\theta dx = \nabla_\theta \int q_\theta dx = \nabla_\theta 1 = 0$).
Using this property, we can derive the true gradients of forward and reverse KL divergences with respect to $\theta$.
Preview: We will later define $k_1 := -\log\frac{p}{q_\theta}$, so the above can be written concisely as $\nabla_\theta D_{\mathrm{KL}}(q_\theta \| p) = \mathbb{E}_{q_\theta}[s_\theta \cdot k_1]$ — this form appears repeatedly in gradient analysis.
Preview: We will later derive $\nabla_\theta k_3 = (1-\frac{p}{q_\theta}) s_\theta$, so $\mathbb{E}_{q_\theta}[\nabla_\theta k_3] = \nabla_\theta D_{\mathrm{KL}}(p \| q_\theta)$ (forward KL). This is why directly backpropagating through $k_3$ produces the “wrong” gradient direction when you intend reverse KL.
With these two results, we can later determine which KL’s true gradient each estimator’s gradient expectation corresponds to.
4. Three Estimators: Definitions and Design Principles
Let $\frac{p(x)}{q_\theta(x)}$ denote the ratio. In a classic note, John Schulman compared three single-sample KL estimators that keep showing up in RLHF and LLM-RL implementations.
4.1 The Three Estimators: Definitions and Intuition
This is the most direct definition: the negative log-ratio. It is unbiased for reverse KL, but the main issue is not that it targets the wrong thing. The issue is that a single sample can be positive or negative. Even when the true KL is small, samples can still swing in both directions, which often leads to large relative variance.
Design motivation: $k_1$ can be either positive or negative; squaring yields an estimator where every sample is non-negative, and each sample measures the magnitude of mismatch between $p$ and $q$.
Why is the bias often small? More precisely, $\mathbb{E}_{q_\theta}[k_2]$ is not reverse KL itself, but near $q_\theta \approx p$ it shares the same second-order local expansion. So it is best understood as a locally useful surrogate; once you leave that small-KL neighborhood, the approximation need not stay reliable.
Technical note: why does $k_2$ share the same second-order local behavior as reverse KL?</summary>
Under the usual regularity conditions, if $q_{\theta_0}=p$ and we perturb by a small $\Delta\theta$, then
Design motivation: We want an estimator that is both unbiased and low variance. A standard approach is to add a control variate to $k_1$—a term with zero expectation that (ideally) is negatively correlated with $k_1$.
Note that $\mathbb{E}_{q_\theta}\left[\frac{p}{q_\theta} - 1\right] = \mathbb{E}_{q_\theta}\left[\frac{p}{q_\theta}\right] - 1 = 1 - 1 = 0$, so for any $\lambda$,
It is always non-negative. This ensures every sample contributes “positively” to the estimate, eliminating the cancellation problem of $k_1$.
Geometric intuition: $k_3$ is actually a Bregman divergence. Consider the convex function $\phi(x) = -\log x$, whose tangent at $x=1$ is $y = 1 - x$. The Bregman divergence is defined as the difference between the function value and the tangent value:
Since a convex function always lies above its tangent, this gap is naturally non-negative. More importantly, as $\frac{p}{q_\theta} \to 1$, the gap shrinks at a second-order rate $\left(\frac{p}{q_\theta} - 1\right)^2$, which is the fundamental reason why $k_3$ tends to have lower variance when the policies are close.
Before discussing bias, variance, and gradients, separate three ways in which the same $k_i$ may be used:
Usage semantics
Question being asked
Typical mistake
KL value metric
Is the expectation the target KL? Is the variance low?
Seeing good value-estimation behavior for $k_3$ and using it everywhere
Differentiable KL loss
Is the backpropagated gradient the gradient of the intended regularizer?
Dropping score-function paths or importance ratios
KL reward shaping
Does the KL sample affect the update only through the policy-gradient term?
Reading a detached reward estimator as if it were a differentiable loss
When the post says a configuration is “correct” or “incorrect,” it is about the gradient induced under that usage, not merely about whether the scalar sample can estimate a KL value.
5. Value Estimation: Bias and Variance
Assume we sample from $q_\theta$ to estimate reverse KL $D_{\mathrm{KL}}(q_\theta \| p)$:
When KL is large ($p = \mathcal{N}(1,1)$, true KL = 0.5):
Estimator
bias/true
stdev/true
$k_1$
0
2
$k_2$
0.25
1.73
$k_3$
0
1.7
Intuitively:
$k_1 = -\log \frac{p}{q}$ has a first-order term; when $\frac{p}{q}$ is close to 1 it can fluctuate substantially and can be negative.
$k_3 = \frac{p}{q} - 1 - \log \frac{p}{q}$ is second-order around $\frac{p}{q}=1$ and is always non-negative, which typically yields lower variance when the policies are close.
Once you leave the small-KL, well-covered regime and $\frac{p}{q}$ can become very large, the variance of $k_3$ can also blow up. At that point the comparison between $k_1$ and $k_3$ is no longer one-sided.
If you only care about KL values, this is the quick picture:
Estimator
Bias for value
Variance characteristics
$k_1$
Unbiased
High (can be +/-)
$k_2$
Biased (often small near KL=0)
Low (always positive)
$k_3$
Unbiased
Low (always positive)
So at the pure value-estimation level, $k_3$ is often the safest choice in the common small-KL, well-covered regime.
Note: To estimate the forward KL value $D_{\mathrm{KL}}(p \| q_\theta) = \mathbb{E}_p\left[\log \frac{p}{q_\theta}\right]$, but only sample from $q_\theta$, use importance sampling $\mathbb{E}_{q_\theta}\left[\frac{p}{q_\theta} \log \frac{p}{q_\theta}\right]$.
6. Two Ways to Use a KL Penalty
The next fork in the road is simply how the KL penalty is used in code. That choice determines whether value-estimation properties are enough, or whether gradient properties become the real issue.
Recall the objective for KL-regularized reinforcement learning (where $\tau \sim q_\theta$ denotes the trajectory distribution induced by policy $q_\theta$):
This mathematical form looks unified, but in actor-critic algorithms (e.g., PPO) it gives rise to two fundamentally different implementation paradigms. They often differ by only a few lines of code, yet correspond to different optimization semantics.
Notation: In this section, we use $\text{KL}_t$ or $\text{KL}(s)$ to generically refer to a token/state-level KL estimator (such as $k_1, k_2, k_3$), with specific definitions from the earlier section “Three Estimators: Definitions and Design Principles”.
6.1 As a Loss Term: KL Backpropagates Directly
actor_loss=-advantage*log_prob+beta*kl# kl participates in gradient
The critic learns only the environment value function; the KL term acts as an explicit regularizer for the actor and participates directly in backpropagation.
6.2 As a Reward-Shaping Term: KL Changes Reward but Does Not Backpropagate
KL is treated as part of the reward via reward shaping, and the actor-critic update is performed on the shaped reward. The KL term itself is detached and does not backpropagate.
In many implementations, these two forms differ by just a .detach(). But optimization-wise they are not the same algorithm. The basic split is:
KL as a loss term: Requires correct gradients for the KL component, including which objective those gradients correspond to.
KL as a reward-shaping term: Requires accurate KL values, and also requires that the induced policy-gradient update matches the intended objective.
7. Gradient Analysis for Differentiable KL Losses
When KL serves as a differentiable loss term, the key question is which objective each estimator actually optimizes through its gradient. This is subtle but central to the theory.
We will keep using the same unified framework, so on-policy and off-policy can be handled in one derivation. Recall the ratio
These basic gradients will be used repeatedly in the unified framework analysis that follows.
“The Gradient of the Mathematical Objective” vs. “The Gradient Returned by Code”
When analyzing estimator gradients, there is a common pitfall: “expect-then-differentiate” and “differentiate-then-expect” need not agree.
If we treat $\mathbb{E}_{q_\theta}[k_i]$ as a function of $\theta$ and differentiate analytically (i.e., “expect-then-differentiate”), then because $\mathbb{E}_{q_\theta}[k_1] = \mathbb{E}_{q_\theta}[k_3] = D_{\mathrm{KL}}(q_\theta \| p)$, we have:
Both yield the reverse-KL gradient. However, when you backpropagate through the sample mean of $k_i$ in code, autograd effectively computes “differentiate-then-expect”, i.e., $\mathbb{E}_{q_\theta}[\nabla_\theta k_i]$, which can differ.
The root cause is that the sampling distribution $q_\theta$ depends on $\theta$, so expectation and differentiation cannot be exchanged naively. This is exactly the subtlety in the on-policy case, and why we introduce the unified $\rho$ framework.
7.2 Gradient Analysis Under the Unified Framework
Now, we use the $\rho$ framework to uniformly handle on-policy and off-policy scenarios. Consider the loss function form $L = \rho \cdot k$, where $\rho = \frac{q_\theta}{\text{sg}(\mu)}$.
From here on, every expectation is with respect to a fixed sampling distribution $\mu$. Under that condition, because $\text{sg}(\mu)$ does not depend on $\theta$, for any differentiable $f_\theta(x)$ we have
So under the $\rho$ framework, “expect-then-differentiate” and “differentiate-then-expect” are equivalent for $\mathbb{E}_\mu[\cdot]$. This does not mean you can freely do the same under $\mathbb{E}_{q_\theta}[\cdot]$.
Gradient Derivations for the Three Estimators Under the Unified Framework
Using $\nabla_\theta \rho = \rho \cdot s_\theta$ (since $\rho = q_\theta / \text{sg}(\mu)$), combined with the previously derived $\nabla_\theta k_i$, applying the product rule:
In other words, the gradient expectation of $\rho k_2$ corresponds to “minimizing $\mathbb{E}_{q_\theta}[k_2]$” (a surrogate with the same local second-order behavior as KL), not the true gradient of reverse KL $D_{\mathrm{KL}}(q_\theta\|p)$; therefore, when the goal is reverse KL, avoid using $\rho k_2$.
Gradient Equivalence: Which Methods Produce Identical Gradient Random Variables
This is also why $\text{sg}(\rho) k_2$ and $\rho k_3$ keep appearing together: for the same sample $x$, they backpropagate the exact same gradient vector, namely $\rho s_\theta k_1$. Not just the same expectation - the same sample-level gradient. So their means, variances, and higher-order statistics all match.
Loss Writing
Gradient Random Variable
Expected Gradient
Optimization Objective
$\rho k_1$
$\rho s_\theta (k_1+1)$
$\nabla D_{\mathrm{KL}}(q \| p)$
Reverse KL ✓
$\rho k_2$
$\rho s_\theta (k_2 + k_1)$
$\nabla_\theta \mathbb{E}_{q_\theta}[k_2]$
Surrogate (not reverse KL) ✗
$\text{sg}(\rho) k_2$
$\rho s_\theta k_1$
$\nabla D_{\mathrm{KL}}(q \| p)$
Reverse KL ✓
$\rho k_3$
$\rho s_\theta k_1$
$\nabla D_{\mathrm{KL}}(q \| p)$
Reverse KL ✓
7.3 A Unified View of On-Policy and Off-Policy
With that in place, the on-policy/off-policy relationship becomes much easier to read.
But the gradients differ, because $\nabla_\theta \rho = s_\theta \neq 0$.
This explains why naive direct backpropagation (i.e., without explicitly constructing $\rho$) fails when using $k_1$ or $k_3$ as the KL loss term in the on-policy case:
Directly using $k_1$ (without $\rho$): $\mathbb{E}_{q_\theta}[\nabla k_1] = \mathbb{E}_{q_\theta}[s_\theta] = 0$, so the KL term is ineffective.
Directly using $k_3$ (without $\rho$): $\mathbb{E}_{q_\theta}[\nabla k_3] = \nabla D_{\mathrm{KL}}(p \| q_\theta)$ (forward KL), i.e., the wrong direction for reverse-KL regularization.
Directly using $k_2$: $\mathbb{E}_{q_\theta}[\nabla k_2] = \nabla D_{\mathrm{KL}}(q_\theta \| p)$ (reverse KL), which makes it the only correct choice under the naive implementation.
If you explicitly construct $\rho = \frac{q_\theta}{\text{sg}(q_\theta)}$, then:
Usable: $\rho k_1$ (higher variance), $\text{sg}(\rho) k_2$ (recommended), and $\rho k_3$ (recommended) all yield reverse-KL gradients.
Not usable: $\rho k_2$ (where $\rho$ participates in the gradient) optimizes a local second-order surrogate rather than the reverse KL.
Usable: $\rho k_1$ (higher variance), $\text{sg}(\rho) k_2$ (recommended), and $\rho k_3$ (recommended) all yield reverse-KL gradients.
Not usable: $\rho k_2$ (where $\rho$ participates in the gradient) optimizes a local second-order surrogate rather than the reverse KL.
The reason $k_2$ works directly in the on-policy case is not a general principle; it is a special degeneration when $\rho \equiv 1$. In that setting, $\nabla_\theta k_2 = k_1 s_\theta$ happens to land on the correct reverse-KL gradient. That should not be extrapolated to general off-policy settings.
Earlier we saw that three choices give unbiased gradients for reverse KL: $\rho k_1$, $\text{sg}(\rho) k_2$, $\rho k_3$. Their gradient random variables are (note that $s_\theta$ is a vector, so the gradient is also a vector):
where $g_\star$ corresponds to both $\text{sg}(\rho) k_2$ and $\rho k_3$ (they are identical).
To avoid ambiguity in “variance of a vector gradient”, we compare the projection variance in any direction: take any unit vector $u$, and define scalar random variables
Once you leave this small-KL neighborhood, however, the sign of $2k_1+1$ is no longer guaranteed. At that point the comparison also depends on the $\rho^2$ weighting and the score-function term, so the local expansion above should not be over-interpreted.
Intuitively:
$g_1 = \rho s_\theta (k_1 + 1)$ contains a zero-mean noise term of magnitude $O(1)$: $\rho s_\theta$
$g_\star = \rho s_\theta k_1$ has eliminated this constant noise term, leaving only first-order terms proportional to $\varepsilon$
$\text{sg}(\rho) k_2$ and $\rho k_3$ give the same gradient random variable. By contrast, $\rho k_1$ carries an extra zero-mean constant-noise term, which is why it is usually noisier in the small-KL regime.
Practical recommendation: For optimizing reverse KL, prefer $\rho k_3$ or $\text{sg}(\rho) k_2$ (both have equivalent gradients and low variance); $\rho k_1$ is unbiased but has higher variance, and can serve as a fallback with clipping/regularization.
Warning (extreme off-policy mismatch):
When $\mu$ differs greatly from $q_\theta$ — for example, when $\mu$ has almost no samples in high-density regions of $q_\theta$, or when $\rho = q_\theta / \mu$ explodes in the tails — any $\rho$-based method will suffer from severe variance issues. In such cases, the advantage of $\rho k_3$ (or $\text{sg}(\rho) k_2$) over $\rho k_1$ is no longer theoretically guaranteed, and strategies like clipping and regularization must be combined.
In the local-policy-update theory usually assumed here, we control the KL constraint and limit the degree of off-policy sampling (e.g., using a nearby policy $\mu = q_{\theta_\text{old}}$). In this local regime, we can say with confidence:
If you’ve decided to use importance sampling to optimize reverse KL, we recommend using $\rho k_3$ or $\text{sg}(\rho) k_2$ (both have equivalent gradients and low variance); in comparison, $\rho k_1$ has higher variance.
This is also how the DeepSeek v3.2 technical report’s “unbiased KL estimate” lines up with the notation here: they use $\frac{q_\theta}{\mu} k_3$, i.e. $\rho k_3$, to recover both unbiased KL estimation and the correct reverse-KL gradient.
Under the unified framework, the gradient targets are:
Sampling Type
Loss
Expected $\nabla_\theta$ Loss
Optimization Objective
Usable for Reverse KL?
on/off-policy
$\rho k_1$
$\nabla_\theta D_{\mathrm{KL}}(q \| p)$
Reverse KL
✓ (higher variance)
on/off-policy
$\rho k_2$
$\nabla_\theta \mathbb{E}_{q_\theta}[k_2]$
Surrogate (not reverse KL)
✗
on/off-policy
$\text{sg}(\rho) k_2$
$\nabla_\theta D_{\mathrm{KL}}(q \| p)$
Reverse KL
✓ (recommended, low variance)
on/off-policy
$\rho k_3$
$\nabla_\theta D_{\mathrm{KL}}(q \| p)$
Reverse KL
✓ (recommended, low variance)
where $\rho = \frac{q_\theta}{\text{sg}(\mu)}$. When on-policy ($\mu = q_\theta$), $\rho \equiv 1$.
It must be emphasized: the conclusions in the table above apply to the unified framework where “loss is written as $L=\rho\,k$ and $\rho$ retains its gradient path in the computation graph”. In the on-policy case, although $\rho \equiv 1$ numerically, since $\rho=\frac{q_\theta}{\text{sg}(q_\theta)}$, we still have $\nabla_\theta\rho=s_\theta\neq 0$, so $\rho k$ and “directly backpropagating through the sample mean of $k$” are not equivalent in terms of gradients.
If you use the naive on-policy implementation (i.e., after sampling from $q_\theta$, treat $\{k_i(x)\}$ as ordinary scalars and directly backpropagate through their sample mean; without explicitly constructing $\rho=\frac{q_\theta}{\text{sg}(q_\theta)}$ to restore the score-function path), then it degenerates to:
Directly using $k_1$: $\mathbb{E}_{q_\theta}[\nabla k_1]=0$ (ineffective)
Directly using $k_2$: $\mathbb{E}_{q_\theta}[\nabla k_2]=\nabla D_{\mathrm{KL}}(q_\theta\|p)$ (reverse KL) ✓
Directly using $k_3$: $\mathbb{E}_{q_\theta}[\nabla k_3]=\nabla D_{\mathrm{KL}}(p\|q_\theta)$ (forward KL) ✗
Compressed into one short list:
On-policy optimization of reverse KL (naive direct backprop implementation): The only correct choice is $k_2$
Off-policy optimization of reverse KL: Three correct options:
$\rho k_1$: Unbiased but higher variance
$\text{sg}(\rho) k_2$: Unbiased, gradient identical to $\rho k_3$
$\rho k_3$: Unbiased and lower variance (equivalent to the above, both recommended)
$\rho k_2$ (weight participates in gradient) fails: This is an easily overlooked pitfall
8. Gradient Analysis for KL Reward Shaping
This is where the easiest mistake happens. Since both $k_1$ and $k_3$ are unbiased as reverse-KL value estimators, it is tempting to think that either one should be fine once detached and used inside reward shaping.
That inference is wrong. Value unbiasedness does not imply gradient correctness inside reward shaping. Once KL becomes part of shaped reward, the relevant object is $\mathbb{E}[s_\theta \hat{k}]$, not $\mathbb{E}[\hat{k}]$.
8.1 The True KL-Regularized Policy Gradient
Consider the KL-regularized reinforcement learning objective:
For the next few paragraphs, focus only on the policy-gradient term itself. I am not folding in extra effects from learned critics, GAE, baseline fitting error, or normalization. In that simplified setting, when we use some estimator $\hat{k}$ (with stop-gradient) inside reward shaping, the shaped reward is $\tilde{R} = R - \beta \cdot \text{sg}(\hat{k})$, and the policy gradient becomes:
When $k_3$ is used in reward shaping, the gradient is biased, with the bias term equal to the negative of the forward KL gradient.
More precisely, using $k_3$ inside reward shaping mixes an extra bias term related to the forward-KL gradient into the reverse-KL update. The resulting update therefore no longer corresponds to pure reverse-KL regularization. This conclusion follows from the gradient decomposition itself and does not depend on any particular experiment.
Using $k_2$ as Penalty: Also Biased
When $\hat{k} = k_2 = \frac{1}{2}k_1^2$, the KL part of the induced policy-gradient term becomes
The unbiasedness condition remains $\mathbb{E}_{q_\theta}[s_\theta \cdot k] = \mathbb{E}_{q_\theta}[s_\theta \cdot k_1]$, exactly the same as on-policy.
One point is worth making explicit here: in the token/sample-level off-policy policy-gradient term discussed in this post, the importance weight $\frac{q_\theta}{\mu}$ multiplies the whole policy-gradient estimator. There is no need to additionally importance-weight the KL scalar inside the shaped reward. Therefore:
Shaped reward keeps its original form: $\tilde{R} = R - \beta \cdot k_1$ (not $R - \beta \cdot \frac{q_\theta}{\mu} k_1$)
Under the stop-gradient reward shaping ($\tilde{R}=R-\beta\,\text{sg}(k)$) with the reverse-KL regularization setting discussed in this post, the conclusion is the same as in the on-policy case: use $k_1$, not $k_3$.
Note: This discussion assumes the usual current-sample / current-token reward-shaping form. In a general multi-step MDP, a fully rigorous off-policy derivation also needs per-step importance weighting or the corresponding value-function correction.
8.2 The Conclusion of This Section: Only $k_1$ Stays Unbiased
Estimator
Value unbiased?
Policy-gradient term unbiased under stop-grad reward shaping?
Actual performance
$k_1$
✓
✓
Stable
$k_2$
✗
✗
Not advised
$k_3$
✓
✗
Notably unstable
Stepping back, value unbiasedness and gradient correctness are two separate axes. For the stop-gradient reward-shaping setup discussed here, only $k_1$ gives the correct policy-gradient term for reverse-KL regularization. Even though $k_3$ is value-unbiased and often lower variance, using it in reward shaping introduces a biased update and is indeed more prone to instability in practice.
Scope reminder: once you add a learned critic, GAE, baseline normalization, and other implementation details, additional bias sources appear. The conclusion here is intentionally about the policy-gradient term itself.
At this point, an apparent tension may arise:
In reward shaping we emphasize “only use $k_1$”;
But in the earlier loss-term backpropagation discussion (especially off-policy), we recommend using $\rho k_3$ or $\text{sg}(\rho)k_2$ for lower-variance reverse-KL gradients.
Let me explain why these are not contradictory: for the KL regularization term’s contribution to the policy-gradient update, the two implementations can be sample-wise equivalent. The practical differences arise mainly from whether the KL term enters the advantage/baseline and from the resulting credit-assignment pathway.
8.3 $k_1$ in Reward Shaping vs. Low-Variance KL Losses
At this point the natural question is: in what sense is “KL in loss” equivalent to “KL in reward”, and in what sense is it not?
Sample-Level Equivalence of the KL Gradient Term
The equivalence discussed here is only about the gradient random variable coming from the KL regularization term itself. Once you add learned critics, baselines, GAE, or batch centering, the overall update semantics split again. We write everything in the ascent direction $\nabla_\theta J$ (if you minimize a loss in code, that is just a global sign flip), and keep the same unified notation: samples come from $x \sim \mu$, and the importance weight $\rho = \frac{q_\theta}{\text{sg}(\mu)}$ multiplies the policy-gradient estimator.
KL as a loss term (low-variance choice): We proved earlier that when using $\text{sg}(\rho) k_2$ or $\rho k_3$ as the regularization term, the gradient random variable simplifies to
KL as reward shaping ($k_1$ in reward): The shaped reward is $\tilde{R} = R - \beta \cdot k_1$ (applying stop-gradient to $k_1$ just avoids direct KL backpropagation in implementation; it does not change the numerical penalty itself). In the policy-gradient term, the KL contribution is
This is why sections 8.1 / 8.2 above and chapter 7 (loss-term analysis) are not actually in conflict: at this level, the KL gradient terms from both approaches are identical sample by sample.
In other words, ignoring the specific construction details of baseline/advantage:
“Writing KL into loss with low-variance implementation ($\text{sg}(\rho)k_2$ or $\rho k_3$)”
and “Writing KL into reward with $k_1$ (stop-gradient shaped reward)”
can exert exactly the same KL regularization “force” on policy updates.
Specifically, if we only look at the gradient term contributed by KL penalty when “maximizing $J$” (the penalty term carries a negative sign in $J$, so the ascent direction naturally carries $-\beta$):
Loss implementation (low-variance form): $-\beta \cdot \rho s_\theta k_1$
They are the same random variable, not merely equal in expectation.
Where the Two Implementations Still Differ
Although the KL gradient terms are sample-level equivalent, the overall update semantics of the two approaches still differ. The differences mainly manifest in the following aspects:
1. Whether KL Enters Advantage/Baseline
KL as a loss term (equivalent to maximizing $J(\theta) = \mathbb{E}[R] - \beta\,\mathrm{KL}$, but implementing the KL term as an independent, controllable force):
KL is an independent regularization term, completely decoupled from advantage. The magnitude of the KL gradient depends only on $k_1$ itself, unaffected by critic quality or baseline choice.
KL as reward shaping:
$$
\nabla_\theta J_{\text{reward-impl}} = \mathbb{E}_\mu[\rho s_\theta \tilde{A}], \quad \tilde{A} \text{ based on } (R - \beta \cdot k_1)
$$
KL enters advantage computation through shaped reward and gets processed by the baseline. This means:
KL’s influence is modulated by how advantage is constructed
If using a value function baseline, KL’s influence is partially absorbed
From an implementation perspective, the difference can be understood as: the Loss approach estimates “environment return” and “KL regularization” separately; the Reward approach treats KL as part of the return, so it follows all the processing you do to returns (baseline, normalization, clipping, etc.).
2. Credit Assignment: Explicit Regularization vs. Shaped-Reward Coupling
KL as a loss term: Each token/state KL gradient is local, directly affecting the update at that position.
KL as reward shaping: The KL penalty is folded into return/advantage computation and can influence earlier decisions depending on how returns are propagated.
3. Reward-Centered KL: Impact on Gradient Unbiasedness
In LLM RL (such as GRPO, PPO for LLM), a common advantage computation is $A = r - \text{mean}(r)$. When KL is used as reward shaping, whether to include KL in the mean affects gradient unbiasedness.
Let samples be $x_1, \dots, x_n \overset{iid}{\sim} q_\theta$, denote $g_i = \nabla_\theta \log q_\theta(x_i)$, and use $\mathrm{kl}_i$ for the KL penalty scalar of the $i$-th sample, $\bar{\mathrm{kl}} = \frac{1}{n}\sum_j \mathrm{kl}_j$.
No centering ($-\beta\,\mathrm{kl}_i$): The expected KL gradient term is
This is an unbiased gradient of $-\beta \mathbb{E}[\mathrm{KL}]$.
Same-batch mean centering ($-\beta(\mathrm{kl}_i - \bar{\mathrm{kl}})$, including self): Since $\bar{\mathrm{kl}}$ depends on all samples (including $x_i$ itself), the expected gradient becomes
The KL regularization gradient is shrunk by $\frac{1}{n}$, equivalent to a smaller effective $\beta$. This is not strictly unbiased.
Leave-one-out centering ($-\beta(\mathrm{kl}_i - \bar{\mathrm{kl}}_{-i})$): If we use $\bar{\mathrm{kl}}_{-i} = \frac{1}{n-1}\sum_{j \neq i} \mathrm{kl}_j$ instead, then $\bar{\mathrm{kl}}_{-i}$ is independent of $g_i$, giving $\mathbb{E}[g_i \bar{\mathrm{kl}}_{-i}] = 0$, therefore
This remains an unbiased gradient, while enjoying variance reduction from centering.
Conclusion: Same-batch mean centering induces an $O(1/n)$ shrinkage of the KL gradient term (equivalently, a slight reduction in the effective $\beta$). This is typically negligible for large group sizes (e.g., GRPO); for strict unbiasedness while retaining variance reduction, use a leave-one-out mean.
When Should You Choose Which Approach?
Dimension
KL as a loss term
KL as reward shaping
KL gradient form
$\rho s_\theta k_1$ (low-var choice)
$\rho s_\theta k_1$
Coupling w/ Advantage
Fully decoupled
Coupled through shaped reward
KL centering
None (absolute penalty)
Yes ($\text{KL} - \text{mean}(\text{KL})$)
Credit assignment
Local, per-token
May have temporal backprop (impl-dependent)
Suitable for
Want KL as an explicit regularizer
Want KL to flow through shaped reward / advantage
Practical recommendations:
If you want KL to stay as an explicit regularizer — separate from advantage construction and less entangled with critic quality — choose KL as a loss term, using $\text{sg}(\rho) k_2$ or $\rho k_3$. For on-policy scenarios, if you prefer not to explicitly construct $\rho = \frac{q_\theta}{\text{sg}(q_\theta)}$, directly using $k_2$ is simpler and less error-prone.
If you want KL to be part of the shaped reward — so it flows through return / advantage construction together with the task reward — choose KL as reward shaping, using $k_1$.
Based on the above conclusions about “value unbiasedness vs. gradient correctness” and “differences between Loss and Reward implementations”, we now proceed to the quick reference guide and common pitfalls that can be directly applied to code.
9. Theoretical Selection Guide and Common Pitfalls
9.1 Quick Reference for the Three Estimator Definitions
Unbiased for reverse KL $D_{\mathrm{KL}}(q_\theta \| p)$ value?
Variance
$k_1$
✓
High (can be negative)
$k_2$
✗ (often small near KL=0, not exact)
Low
$k_3$
✓
Low
9.3 Common Pitfalls
Using $k_1 = \log \frac{q_\theta}{p}$ directly as a loss term (on-policy): Gradient expectation is zero, completely ineffective.
Using $k_3 = \frac{p}{q_\theta} - 1 - \log \frac{p}{q_\theta}$ as a loss term to optimize reverse KL (on-policy): Its gradient corresponds to forward KL $D_{\mathrm{KL}}(p \| q_\theta)$, i.e. the wrong direction.
Using $\frac{q_\theta}{\mu} k_2$ (importance weight not detached) off-policy: Gradient corresponds to a local second-order surrogate, not reverse KL.
Using $k_3$ inside reward shaping: Although it is value-unbiased, it induces a biased policy-gradient update and introduces extra gradient terms outside the intended reverse-KL update.
Simply setting $\rho$ to constant 1 in on-policy: Must explicitly construct $\rho = \frac{q_\theta}{\text{sg}(q_\theta)}$ (or equivalently $\exp(\log q_\theta - \text{sg}(\log q_\theta))$), otherwise the score-function gradient path is lost, causing $\rho k_1$ and $\rho k_3$ to degenerate to naive forms and fail.
Confusing “value unbiasedness” with “gradient correctness”: $k_3$ is value-unbiased for reverse KL, but when used in reward shaping, the induced policy gradient is biased; both dimensions matter.
10. Summary
If you only remember four lines, make them these:
Value unbiasedness does not imply gradient correctness. Choosing a KL estimator means checking not only how well it estimates KL values, but also what objective its gradient is actually optimizing.
If KL is a differentiable loss term: in the naive on-policy implementation, $k_2$ is the simplest correct choice; if you explicitly construct $\rho$, or if you are off-policy, prefer $\rho k_3$ or $\mathrm{sg}(\rho)k_2$.
If KL is used as stop-gradient reward shaping: in the policy-gradient term analyzed here, only $k_1$ stays aligned with reverse-KL regularization.
A low-variance KL loss and $k_1$ in reward shaping can be sample-wise equivalent on the KL term, but the two algorithms still have different semantics. In the former, KL is an explicit regularizer; in the latter, KL flows through advantage, baselines, and credit assignment.
Kezhao Liu, Jason Klein Liu, Mingtao Chen, Yiming Liu. “Rethinking KL Regularization in RLHF: From Value Estimation to Gradient Optimization”. arXiv:2510.01555. https://arxiv.org/abs/2510.01555
Yifan Zhang, Yiping Ji, Gavin Brown, et al. “On the Design of KL-Regularized Policy Gradient Algorithms for LLM Reasoning”. arXiv:2505.17508. https://arxiv.org/abs/2505.17508
Vedant Shah, Johan Obando-Ceron, Vineet Jain, Brian Bartoldson, Bhavya Kailkhura, Sarthak Mittal, Glen Berseth, Pablo Samuel Castro. “A Comedy of Estimators: On KL Regularization in RL Training of LLMs”. arXiv:2512.21852. https://arxiv.org/abs/2512.21852